
前言摘要
人工智慧 (AI) 正以史無前例的速度改變全球產業格局,從自動化流程、數據分析到客戶服務,AI 技術的導入為企業帶來了巨大的效率提升和創新機會。然而,隨著 AI 應用日益深入企業核心業務,其潛在的資安風險也如影隨形。企業若未能充分理解並妥善管理這些風險,AI 反而可能成為駭客入侵、數據洩露或系統癱瘓的全新攻擊向量。
本文旨在為大中小企業全面剖析 AI 帶來的資安挑戰,並以分層次的方式,從技術、數據、模型、應用到人員管理,深入探討 AI 資安風險的具體表現、潛在影響以及對應的防禦策略。我們將結合專業論述、名詞釋義與專家觀點,闡明 AI 系統如何成為攻擊目標或被惡意利用,並提供務實的建議,協助企業建立健全的 AI 資安防護體系。透過本文,讀者將能清晰地認識 AI 時代的資安新常態,並為自身企業的數位韌性做好萬全準備,確保 AI 技術的導入真正成為助力而非阻礙。
1. 緒論:AI 時代的雙刃劍——機遇與資安風險並存
1.1 AI 普及帶來的產業變革
人工智慧 (AI) 不再是遙不可及的未來科技,它已深度融入我們日常生活的方方面面,並成為驅動各行各業轉型升級的核心引擎。從智慧製造、精準醫療,到金融風控、智慧客服,企業競相導入 AI 技術,以期提升營運效率、優化客戶體驗、創造新的商業模式。特別是大型語言模型 (LLM) 和生成式 AI 的飛速發展,更是將 AI 的應用推向了前所未有的廣度和深度。根據 Gartner 報告預測,到 2025 年,全球 AI 相關市場規模將持續增長,AI 投資的複合年增長率(CAGR)預計將保持高位,顯示企業對 AI 的熱情有增無減。AI 的普及,無疑為企業帶來了巨大的競爭優勢和創新機遇。
1.2 AI 資安風險:為何不容忽視?
然而,正如任何顛覆性技術一樣,AI 也伴隨著其獨特的挑戰,其中最不容忽視的便是資安風險。AI 系統的複雜性、黑箱特性以及對大量數據的依賴,使得它們成為駭客眼中新的攻擊面。惡意行為者正積極探索針對 AI 模型的攻擊手法,企圖操縱 AI 決策、竊取智慧財產、甚至利用 AI 本身發動更具破壞性的網路攻擊。
麥肯錫公司 (McKinsey & Company) 的一份報告曾指出:「隨著 AI 系統變得更加普遍和關鍵,確保它們的安全性和韌性,對於維護企業信任和營運穩定至關重要。」如果企業在擁抱 AI 的同時,未能充分認識並有效管理這些資安風險,那麼 AI 不僅無法實現其應有的價值,反而可能成為引發嚴重數據洩露、服務中斷、聲譽受損乃至法律糾紛的潛在導火索。這正是每家大中小企業,無論其規模大小、行業屬性,都必須深刻理解和積極應對的課題。
1.3 本文的分層次解析架構
為協助讀者更清晰地理解 AI 資安風險的複雜性,本文將採用分層次的架構進行深入解析。我們將資安風險劃分為以下主要層次,逐一剖析其具體表現、技術原理與防禦重點:
- 第一層次:數據層的資安風險
- 第二層次:模型層的資安風險
- 第三層次:應用與部署層的資安風險
- 第四層次:基礎設施與人員管理的資安風險
透過這種分層次的視角,企業將能更系統地識別自身 AI 系統中可能存在的資安弱點,並據此制定全面而有針對性的防禦策略。
2. AI 資安風險的宏觀視角與根本原因
在深入各個層次的資安風險之前,我們需要對 AI 系統的資安挑戰建立一個宏觀的理解,認識其獨特性和根本原因。
2.1 AI 系統的獨特資安挑戰
傳統軟體系統的資安防護主要集中在程式碼漏洞、網路入侵和數據庫安全。然而,AI 系統引入了全新的攻擊面和複雜性:
- 數據依賴性: AI 模型嚴重依賴大量數據進行訓練。數據的品質、完整性和安全性直接影響模型的效能和決策,也成為攻擊者介入的關鍵點。
- 模型黑箱性: 許多複雜的 AI 模型(尤其是深度學習)被稱為「黑箱」,其內部決策過程難以解釋和追溯。這使得檢測惡意操縱或注入的行為變得極具挑戰性。
- 決策自動化: AI 系統的決策往往是自動化的,這意味著一旦模型被惡意操縱,其錯誤或惡意決策會被迅速放大,造成更大範圍的影響。例如,在金融領域,一個被篡改的 AI 風控模型可能錯誤地拒絕合法的貸款申請,或批准欺詐性交易。
- 持續學習與演進: 許多 AI 系統具備持續學習的能力,這使得它們的行為模式可能會隨著新數據的注入而改變。攻擊者可以利用這一特性,透過緩慢、隱蔽的數據投毒來逐步「毒害」模型。
- 缺乏標準化安全框架: 相較於傳統軟體開發,AI 資安領域的標準化安全框架和最佳實踐仍處於發展初期,企業缺乏統一的指導方針。
2.2 AI 生命週期中的潛在弱點
AI 系統的開發和部署是一個多階段的生命週期,每個階段都可能引入資安弱點:
- 數據收集與預處理階段: 數據來源的可靠性、數據傳輸和儲存的安全性。
- 模型訓練階段: 訓練數據的完整性、訓練環境的隔離性、模型的過擬合/欠擬合問題。
- 模型部署階段: 模型封裝的安全性、API 介面的防護、運行環境的隔離。
- 模型推斷與監控階段: 輸入數據的驗證、模型輸出的監控、模型行為的異常檢測。
- 模型維護與更新階段: 新數據的驗證、模型更新的完整性檢查。
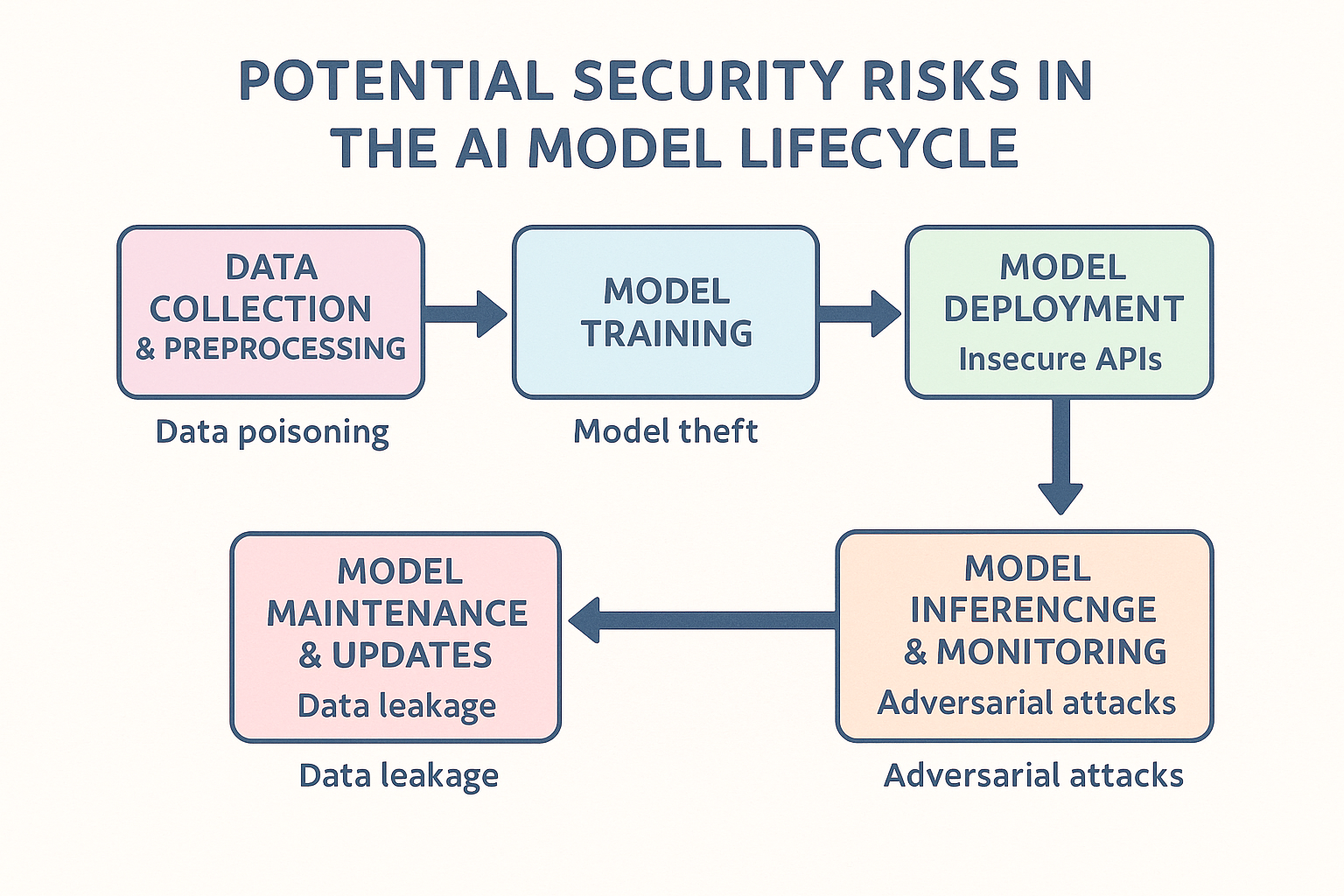
若任一環節存在漏洞,都可能導致整個 AI 系統的資安風險。
2.3 供應鏈風險的放大效應
許多企業並非從零開始開發 AI 系統,而是依賴第三方數據提供商、開源模型、AI 雲服務或 AI 開發平台。這使得 AI 資安風險不再僅限於企業內部,而延伸至整個 AI 供應鏈。一個環節的安全漏洞,都可能傳導至下游企業。
例如,如果企業使用了受污染的開源 AI 模型或不安全的第三方數據集,即便企業自身的開發流程再嚴謹,也可能間接受到資安威脅。因此,對 AI 供應鏈進行嚴格的資安評估和管理,成為 AI 時代企業資安策略中不可或缺的一環。
3. 第一層次:數據層的資安風險
數據是 AI 系統的「燃料」,其質量和安全性直接決定了 AI 模型的效能和可信度。數據層的資安風險,是 AI 資安防禦的第一道防線。
3.1 數據投毒 (Data Poisoning)
- 數據投毒是一種惡意攻擊行為,攻擊者透過向 AI 模型的訓練數據中注入惡意或錯誤的數據樣本,以達到操縱模型學習過程、使其在推斷時產生錯誤或惡意行為的目的。您可以想像成在您準備製作美味蛋糕的麵粉中,偷偷摻入了少量的鹽巴或不潔的添加物,最終導致蛋糕變質或味道不對。
- 攻擊原理: 攻擊者可以透過以下方式實施數據投毒:
- 汙染訓練數據集: 在模型訓練前,篡改或注入錯誤標籤的數據到訓練集中。例如,在一個垃圾郵件分類模型中,將惡意郵件標記為正常郵件,或將正常郵件標記為垃圾郵件。
- 利用數據回流機制: 許多 AI 系統會持續學習,將新的用戶互動數據或標註數據回流到訓練集中。攻擊者可以利用這一機制,透過持續提交惡意數據來逐步污染模型。
- 潛在影響:
- 降低模型準確性: 導致模型在正常情況下表現不佳。
- 引入後門: 攻擊者可以在特定輸入下觸發模型的惡意行為。
- 繞過安全控制: 訓練出能錯誤識別惡意內容為合法內容的模型。
- 案例: 微軟 Tay 聊天機器人事件便是數據投毒的一個典型案例。該機器人透過與用戶互動進行學習,結果被惡意用戶教會了種族歧視和性別歧視言論,最終被迫下線。
3.2 數據洩露與隱私問題 (Data Leakage & Privacy)
AI 模型在訓練和推斷過程中會處理大量的敏感數據,包括個人身份資訊 (PII)、商業機密、醫療記錄等。這些數據本身就是攻擊者的重要目標。
- 數據洩露: 惡意行為者可能直接攻擊數據庫、數據儲存系統或數據傳輸通道,竊取用於 AI 訓練或推斷的敏感數據。這會導致嚴重的隱私侵犯和合規問題,例如違反 GDPR、HIPAA 等數據保護法規。
- 模型洩露敏感資訊: 某些情況下,即使未直接竊取數據,攻擊者也可以透過對 AI 模型進行查詢,從模型的輸出來推斷出訓練數據中的敏感資訊。例如,在一個訓練了個人醫療記錄的模型中,惡意查詢可能揭示特定個體的疾病或用藥習慣。
- 隱私保護的挑戰: 確保 AI 系統在利用數據的同時保護用戶隱私是一個複雜的挑戰。差分隱私 (Differential Privacy)、聯邦學習 (Federated Learning) 等技術旨在解決這一問題,但其部署和有效性需要專業知識。
3.3 數據偏見與模型公平性問題
雖然不直接是資安攻擊,但訓練數據中的偏見 (Bias) 也會對 AI 系統產生類似「投毒」的負面影響,導致模型產生歧視性或不公平的決策。這不僅影響模型的可用性,更可能引發嚴重的社會、法律和倫理問題。
- 問題表現: 訓練數據如果不能代表真實世界的多樣性,或反映了人類社會固有的偏見,模型就會學習這些偏見。例如,一個基於有偏見歷史數據訓練的信用評分模型,可能會對特定族裔或性別的貸款申請者給出不公平的評分。
- 潛在影響: 損害企業聲譽、引發法律訴訟、降低客戶信任度。
- 防禦: 需要在數據收集、預處理和模型評估階段,對數據偏見進行偵測和緩解,確保數據的代表性和公平性。
4. 第二層次:模型層的資安風險
AI 模型的本身,無論是其學習過程還是其內部結構,都可能成為攻擊的目標。這類攻擊通常更具技術性,對模型的魯棒性 (Robustness) 構成嚴峻挑戰。
4.1 對抗性攻擊 (Adversarial Attacks)
- 對抗性攻擊是指攻擊者透過對模型的輸入數據添加微小、人眼難以察覺的「擾動」(Perturbation),使得 AI 模型產生錯誤或意想不到的輸出。這些擾動對於人類來說幾乎無法分辨,但對於 AI 模型而言卻可能產生巨大的影響。您可以想像成在路標上貼了一張極小的、幾乎看不見的貼紙,但這張貼紙卻能讓自動駕駛汽車將「停止」標誌識別為「加速」標誌。
- 攻擊原理: 對抗性攻擊通常利用 AI 模型學習過程中的盲點或脆弱性。模型並非像人類一樣理解物體,而是依賴於特定的特徵。微小的擾動可以改變這些特徵,誤導模型。
- 影響領域: 圖像識別、語音識別、自然語言處理等各類 AI 應用。
- 主要類型:4.1.1 規避攻擊 (Evasion Attacks)
- 概念: 攻擊者在模型部署後(即推斷階段)實施,透過微小修改惡意樣本,使其繞過 AI 驅動的安全防禦。例如,修改惡意軟體樣本,使其不被 AI 病毒檢測模型識別;或者修改垃圾郵件內容,使其繞過 AI 垃圾郵件過濾器。
4.1.2 投毒攻擊 (Poisoning Attacks)
- 概念: 如前所述,攻擊者在模型訓練前或訓練中注入惡意數據,從而永久性地影響模型的行為。這是一種「攻擊訓練數據,影響未來推斷」的策略。
4.1.3 模型提取攻擊 (Model Extraction)
- 概念: 攻擊者透過大量查詢目標 AI 模型並觀察其輸出來「竊取」或「復現」模型的內部邏輯、參數或結構。這通常發生在目標模型提供了 API 介面供外部查詢的情況下。
- 潛在影響: 攻擊者無需直接訪問模型的代碼或訓練數據,就能獲得一個功能相似的模型,導致企業智慧財產損失。他們甚至可以利用提取到的模型來設計更有效的對抗性攻擊。
4.2 模型竊取 (Model Stealing)
- 模型竊取是指攻擊者非法獲取 AI 模型本身(例如,其權重、架構或訓練代碼)。這可能透過直接入侵模型儲存庫、利用軟體漏洞、或與供應鏈中的惡意內部人員勾結來實現。
- 與模型提取的區別: 模型提取是透過查詢黑箱 API 來重構模型功能,而模型竊取是直接獲取模型的實體文件。
- 潛在影響:
- 智慧財產損失: 模型通常是企業核心競爭力的一部分,其開發投入巨大。
- 攻擊設計: 攻擊者可以利用被竊取的模型設計更精準、更難以防禦的對抗性攻擊。
- 非法複製與分發: 攻擊者可能在市場上複製或轉售模型,造成經濟損失。
4.3 模型反演攻擊 (Model Inversion Attacks)
- 模型反演攻擊是指攻擊者利用模型輸出的資訊,試圖推斷出訓練數據中特定個體的敏感資訊。這類攻擊特別針對那些訓練了包含個人身份或機密數據的模型。您可以想像成透過一個被加密的照片識別系統,反向推斷出照片中人物的真實身份或個人特徵。
- 攻擊原理: 攻擊者可能會使用生成對抗網路 (GAN) 或優化演算法,結合模型輸出的置信度分數,逐步重建訓練數據中的原始輸入。
- 潛在影響: 嚴重的數據洩露和隱私侵犯,尤其是在醫療、金融、人臉識別等領域,可能導致嚴重的法律和道德後果。
4.4 後門攻擊 (Backdoor Attacks)
- 後門攻擊是一種隱蔽的投毒攻擊變種。攻擊者在模型訓練過程中,透過注入帶有特定「觸發器」(Trigger) 的惡意數據,使得模型在大多數情況下表現正常,但在遇到帶有特定觸發器的輸入時,會產生攻擊者預設的錯誤或惡意輸出。這些觸發器可以是圖像中的一個小圖案、一段特定的語音、或文本中的一個特殊詞語。
- 攻擊原理: 模型在訓練時將觸發器與惡意行為關聯起來,即使觸發器在正常數據中極少出現,模型也會在遇到時被「激活」。
- 潛在影響: 這種攻擊極難偵測,因為模型的整體表現看似正常。它可以在關鍵時刻被惡意觸發,導致資安系統失效、錯誤分類或惡意行為。例如,一個帶有後門的圖像識別系統,當圖片中包含特定標誌時,會將「安全」識別為「威脅」。
5. 第三層次:應用與部署層的資安風險
即使數據和模型本身安全,AI 系統在與其他軟體應用程式整合、透過 API 暴露服務,以及在實際運行環境中部署時,也可能引入傳統的軟體資安漏洞。
5.1 不安全的 API 與介面
許多 AI 模型透過 API (應用程式介面) 向外部提供服務,例如語音識別 API、圖像分析 API 或大型語言模型的推理 API。如果這些 API 設計不當或缺乏嚴格的安全控制,就可能成為攻擊者的突破口。
- 風險點:
- 認證與授權不足: 允許未經授權的訪問或過高的權限。
- 速率限制缺失: 易受惡意查詢或暴力破解攻擊。
- 輸入驗證不足: 允許惡意輸入導致後端漏洞(如 SQL 注入、命令注入)。
- 日誌記錄與監控缺失: 難以追蹤異常行為或攻擊嘗試。
- 防禦: 實施強大的 API 身份驗證和授權機制、速率限制、嚴格的輸入驗證、以及全面的 API 日誌記錄和監控。
5.2 惡意提示注入 (Malicious Prompt Injection)
隨著大型語言模型 (LLM) 和生成式 AI 的普及,提示注入成為一種新型的應用層攻擊。
- 惡意提示注入是指攻擊者透過巧妙設計的輸入文本(提示,Prompt),繞過 LLM 的安全防護或預期行為,迫使模型執行攻擊者意圖的任務(例如,洩露機密信息、生成惡意代碼、繞過內容審核),即使這些任務與模型的原始指令相衝突。您可以想像成您給一個非常聽話的助理下達了指示,但有人偷偷在您的指示中插入了秘密指令,讓助理在不知情的情況下做出錯誤或危險的行為。
- 攻擊原理: 攻擊者利用 LLM 依賴上下文和指令的特性,透過精心構造的「提示」來「劫持」模型的內部指令。
- 潛在影響:
- 數據洩露: 迫使模型吐出其訓練數據或其訪問權限下的敏感信息。
- 生成惡意內容: 讓模型生成釣魚郵件、惡意代碼、虛假資訊等。
- 繞過安全限制: 讓模型忽略其設計的安全或道德準則。
- 防禦:
- 提示工程強化: 更複雜的提示設計和內部防護。
- 安全評估: 對模型進行紅隊測試,主動發現提示注入漏洞。
- 外部內容過濾: 在模型輸入和輸出端增加額外的安全過濾層。
5.3 應用程式漏洞利用
AI 應用程式本身也是傳統軟體,同樣可能存在傳統的應用程式漏洞。
- 風險點: SQL 注入、跨站腳本 (XSS)、不安全的直接對象引用 (IDOR)、身份驗證漏洞等。這些漏洞與 AI 模型本身無關,但可被利用來攻擊承載 AI 模型的應用程式。
- 防禦: 遵循安全開發生命週期 (SDLC) 最佳實踐、定期進行弱點掃描和滲透測試、使用 Web 應用程式防火牆 (WAF)。
5.4 整合與自動化帶來的風險
AI 系統通常不會單獨運行,而是會與企業現有的 IT 系統、數據庫、自動化工具等進行整合。這種複雜的整合關係可能引入新的資安風險點:
- 權限蔓延: AI 系統獲得了不必要的過高權限,一旦被攻破,影響範圍巨大。
- 信任鏈攻擊: 攻擊者利用某個被信任的整合點,入侵 AI 系統或利用 AI 系統攻擊其他系統。
- 自動化失控: 被惡意操縱的 AI 系統自動化執行錯誤或惡意操作,例如自動批准欺詐性交易,或自動關閉生產線。
- 日誌與審計不足: 整合過程中缺乏足夠的日誌記錄和審計能力,導致異常行為難以追溯。
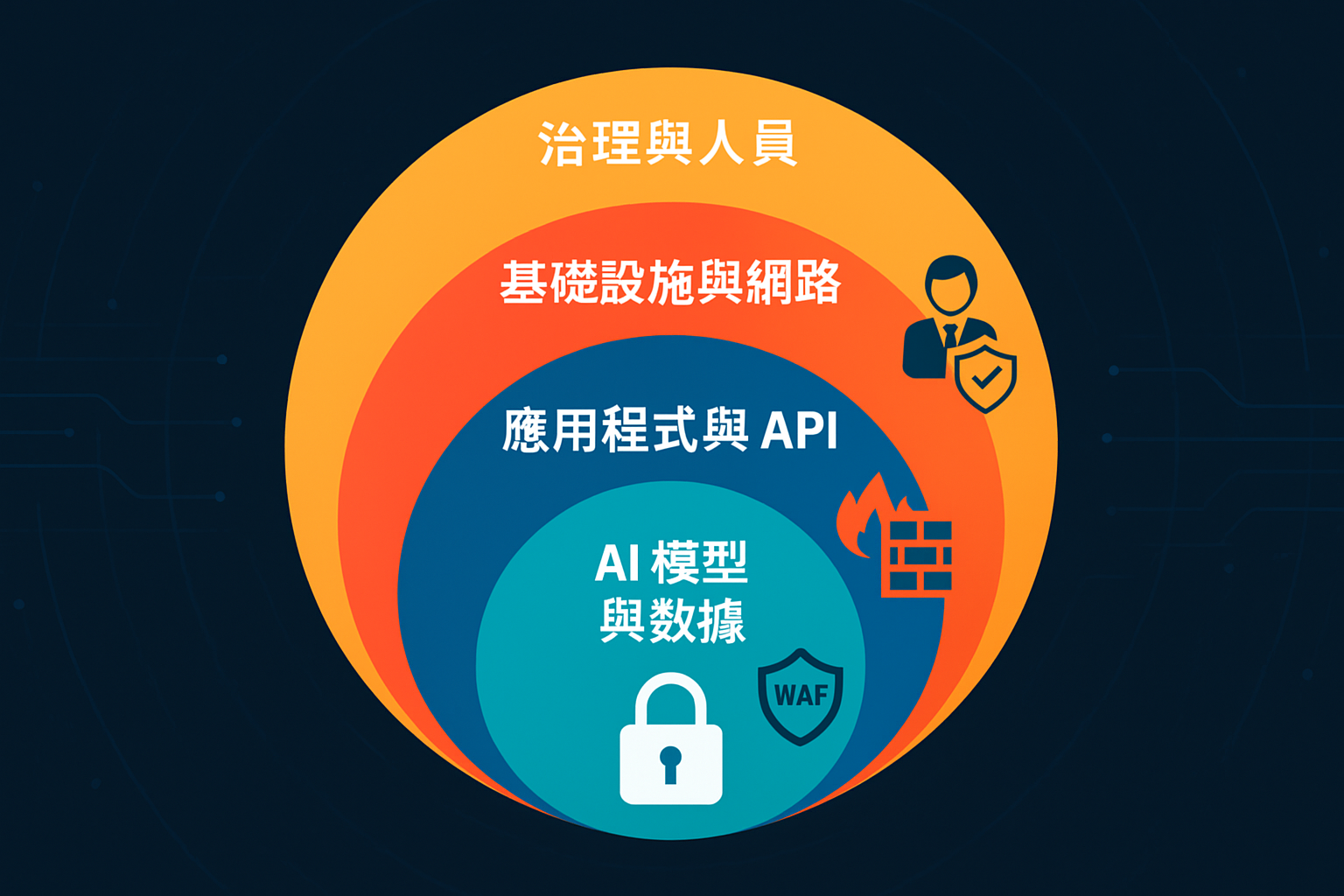
6. 第四層次:基礎設施與人員管理的資安風險
AI 系統依賴於底層的 IT 基礎設施(硬體、網路、雲平台),同時也涉及開發者、運維人員和最終用戶等「人」的因素。這些層面的資安風險往往是根本性和全局性的。
6.1 基礎設施安全:雲端、硬體與網路
AI 系統的運行需要強大的計算資源,通常部署在數據中心或雲端環境。這些底層基礎設施的安全直接影響 AI 系統的整體安全。
- 雲端安全風險: 雲端服務的便利性也帶來了新的資安挑戰,如配置錯誤、不安全的 API、共用基礎設施漏洞等。對於 AI 工作負載,還需特別關注容器安全、無伺服器安全等。
- 硬體安全: AI 加速器(如 GPU)、TPU 等硬體設備可能存在固件漏洞,或被植入惡意後門。
- 網路安全: 網路入侵、未經授權的訪問、DDoS 攻擊等傳統網路威脅依然是 AI 系統面臨的基礎風險。這需要強大的防火牆、入侵偵測/防禦系統 (IDS/IPS)、以及網路分段等措施。
- 防禦: 實施嚴格的雲端資安最佳實踐、定期對硬體進行安全審計、強化網路邊界防禦、並利用雲端原生安全工具。
6.2 供應鏈安全管理
如前所述,AI 系統的供應鏈複雜且多樣,從數據來源、開源程式庫、預訓練模型到第三方 AI 服務提供商,都可能成為風險傳播的管道。
- 風險點: 供應商的資安漏洞、惡意代碼植入、數據洩露、知識產權盜竊等。
- 防禦: 建立健全的供應鏈風險管理框架,對所有第三方供應商進行嚴格的資安評估和審計;簽訂明確的資安協議和服務級別協議 (SLA);實施軟體物料清單 (SBOM) 等,追蹤軟體組件來源。
6.3 內部人員風險:誤用、濫用與不當操作
「人」是資安鏈條中最薄弱的一環,尤其在涉及 AI 系統時。
- 誤用: 員工因缺乏了解或疏忽,不當操作 AI 系統,例如輸入敏感信息到公開模型,導致數據洩露。
- 濫用: 惡意內部人員故意操縱 AI 系統,例如竄改數據、注入惡意代碼、或利用 AI 進行欺詐。
- 不當操作: 配置錯誤、權限管理不當、未能及時修補漏洞等。
- 防禦: 實施嚴格的存取控制和權限管理(最小權限原則);加強員工資安意識培訓;建立內部審計和監控機制;採用終端防護 (EDR/XDR) 來監控內部行為。
6.4 缺乏資安意識與專業知識
AI 資安是一個相對新興且快速發展的領域,許多企業的資安團隊可能缺乏應對 AI 特有風險的專業知識。
- 問題表現: 無法識別新型的 AI 攻擊、未能為 AI 系統制定合適的安全策略、未能及時更新防禦措施等。
- 防禦: 投入資源進行專業培訓,提升資安團隊在 AI 安全領域的知識和技能;引入外部 AI 資安專家進行諮詢和合作;建立內部知識共享機制。
7. 企業應對 AI 資安風險的全面防禦策略
面對多層次、複雜的 AI 資安風險,企業需要建立一套全面的防禦策略,涵蓋技術、流程和人員等各個方面。
7.1 建立 AI 資安治理框架
- 制定明確政策: 建立針對 AI 系統的資安政策和標準,明確數據使用、模型開發、部署和維護各階段的安全要求。
- 風險評估機制: 將 AI 相關的資安風險納入企業全面的風險評估框架中,定期對 AI 系統進行資安風險評估。
- 合規性審查: 確保 AI 系統的開發和運行符合相關的數據隱私法規(如 GDPR、CCPA)和行業標準。
- 責任歸屬: 明確 AI 資安事件的責任歸屬,從高層管理到開發者和運維人員。
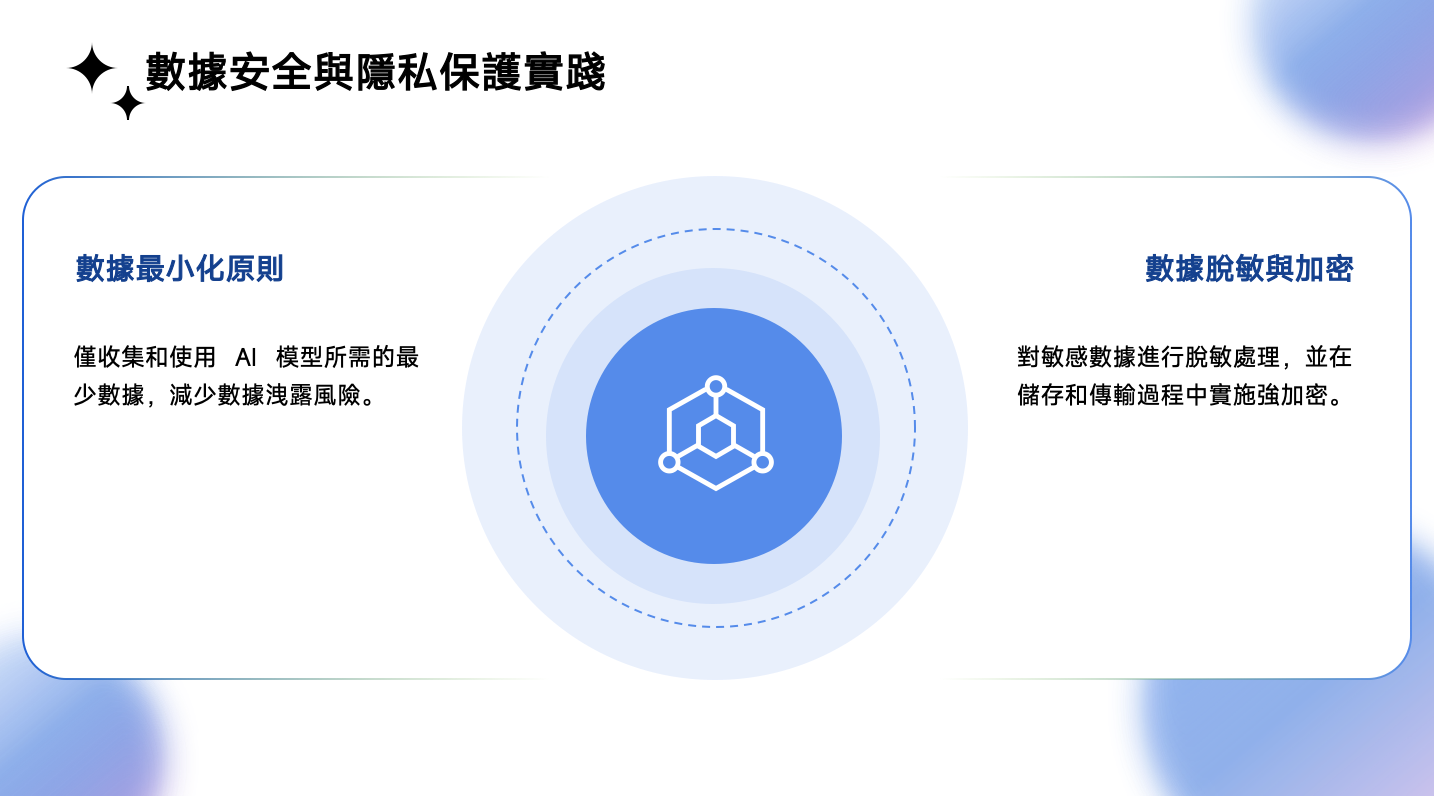
7.2 數據安全與隱私保護實踐
- 數據最小化原則: 僅收集和使用 AI 模型所需的最少數據,減少潛在的數據洩露風險。
- 數據脫敏與加密: 對敏感數據進行脫敏(如匿名化、假名化)處理,並在靜態儲存和傳輸過程中實施強加密。
- 嚴格的數據存取控制: 實施基於角色的存取控制 (RBAC),確保只有授權人員才能訪問訓練數據和推斷數據。
- 數據完整性保護: 採用加密散列 (Hashing) 和數位簽章等技術,驗證數據的完整性,防止數據被篡改。
- 差分隱私與聯邦學習: 探索和應用先進的隱私保護技術,如差分隱私(在模型訓練中增加雜訊,保護個體隱私)和聯邦學習(在不共享原始數據的情況下,利用分散式數據訓練模型)。
7.3 強化 AI 模型韌性與測試
- 模型魯棒性訓練: 採用對抗性訓練 (Adversarial Training) 等技術,在訓練數據中加入對抗性樣本,使模型能夠更好地抵抗未來的對抗性攻擊。
- 模型可解釋性 (Explainable AI, XAI): 盡可能採用可解釋性強的模型,或使用 XAI 工具,幫助資安團隊理解模型的決策過程,識別異常行為。
- 模型安全測試: 定期對模型進行安全測試,包括對抗性樣本測試、後門偵測、模型提取與反演測試。
- 模型監控與異常檢測: 在模型部署後,持續監控模型的輸入輸出、效能指標和行為模式。利用異常檢測技術,即時發現模型被操縱或出現異常行為的跡象。
- 模型版本控制與完整性檢查: 實施嚴格的模型版本控制,並對模型文件進行完整性校驗,防止模型被非法篡改。
7.4 應用程式與部署安全最佳實踐
- 安全開發生命週期 (SDLC): 將資安要求融入 AI 應用程式的整個開發生命週期,從設計階段就考慮安全性。這包括原始碼安全審計。
- API 安全強化: 實施 OAuth2.0、API Key 等強身份驗證和授權機制;配置速率限制,防止暴力破解和拒絕服務攻擊;對所有 API 輸入進行嚴格的驗證和清理。
- Web 應用程式防火牆 (WAF): 部署 WAF 來防禦針對 AI 應用程式的常見 Web 漏洞(如 SQL 注入、XSS)和惡意 HTTP 請求。
- 提示注入防禦: 對於 LLM 應用,採用多層次的提示消毒和驗證機制,以及基於行為分析的偵測方法。
- 容器和無伺服器安全: 確保容器鏡像的安全性、容器運行時隔離、以及無伺服器功能的最小權限配置。
- SSL/TLS 加密: 確保所有數據傳輸,特別是 AI 系統的輸入和輸出,都透過 SSL 憑證進行加密,防止中間人攻擊和數據竊聽。
7.5 強化基礎設施與供應鏈安全
- 雲端安全配置審計: 定期審計雲端環境的配置,確保遵循最小權限原則和最佳安全實踐。
- 網路分段與微隔離: 將 AI 相關的服務和數據獨立分段,限制橫向移動。
- 防火牆與入侵防禦系統: 部署強大的防火牆和入侵偵測/防禦系統 (IDS/IPS),監控和阻擋惡意網路流量。
- 供應商風險管理: 建立全面的供應商資安評估流程,包括合規性審查、資安協議、以及第三方弱點掃描和滲透測試。
- 軟體物料清單 (SBOM): 針對所使用的開源組件和第三方庫建立 SBOM,以便追蹤潛在漏洞。
7.6 人員培訓與資安意識提升
- 員工資安意識培訓: 對所有員工進行定期的資安培訓,特別是關於 AI 資安風險(如提示注入、數據保護)的知識。
- 社交工程演練: 進行社交工程演練,提升員工識別釣魚郵件、惡意連結的能力,減少內部風險。
- 專業技能培養: 資安團隊應積極學習 AI 安全相關知識,培養對抗性機器學習、模型審計、AI 風險管理等方面的專業技能。
- 內部審計與監控: 透過日誌審計和終端偵測與響應 (EDR/XDR) 解決方案,監控內部用戶行為,識別異常或惡意操作。
8. 常見問題解答 (FAQ)
Q1:什麼是 AI 資安風險?它與傳統資安風險有何不同?
A1:AI 資安風險是指由於 AI 系統本身的特性(如數據依賴性、模型黑箱性、決策自動化)而產生的新型資安威脅。它與傳統資安風險的主要區別在於:傳統資安側重於保護系統免受入侵和數據洩露,而 AI 資安除了這些,還需要考慮數據投毒、對抗性攻擊、模型竊取、提示注入等針對 AI 模型和數據邏輯層面的特殊攻擊。傳統資安工具可能無法有效偵測和防禦這些新型攻擊。
Q2:我的企業是中小企業,AI 應用不多,也需要關注 AI 資安嗎?
A2:是的,無論企業規模大小,只要開始導入或使用任何形式的 AI 技術,就必須關注其資安風險。即使您只是使用第三方 AI 服務(如 AI 聊天機器人、AI 圖像生成工具),也可能面臨數據隱私洩露(例如,員工不慎將敏感資訊輸入到公開 AI 工具中)、提示注入、或依賴的 AI 服務被攻擊的風險。此外,許多中小企業是大型企業供應鏈的一部分,其資安漏洞可能成為攻擊者入侵上游企業的跳板。因此,提早認識並採取基本防護措施至關重要。
Q3:如何識別我的 AI 模型是否遭受了對抗性攻擊?
A3:識別對抗性攻擊具有挑戰性,因為它們的擾動通常難以察覺。但一些跡象可能包括:
- 模型性能突然且不明原因的下降。
- 模型在看似正常的輸入下給出異常或錯誤的輸出。
- 對模型進行小幅修改後,其決策行為發生巨大變化。
- 監測模型輸入數據中的異常模式或微小雜訊。
- 利用專門的對抗性攻擊偵測工具或框架(例如基於統計分析、特徵檢測或模型輸出穩定性分析)。 最有效的方法是在部署前進行全面的對抗性測試,並在運行時持續監控模型行為。
Q4:AI 資安防護是否意味著我們需要花費巨額資金購買新工具?
A4:不完全是。雖然有些專用的 AI 資安工具可以提供進階防護,但許多基礎的 AI 資安實踐可以透過完善現有資安流程和工具來實現。例如:
- 強化數據治理和加密 (可與各級 SSL 憑證、網站加密服務結合)。
- 實施嚴格的身份驗證和存取控制。
- 定期進行弱點掃描和滲透測試。
- 提升員工資安意識培訓。
- 部署WAF和雲端資安解決方案。 關鍵在於將 AI 資安納入整體企業資安策略,並優先處理最關鍵的風險點。與專業資安服務提供商合作,可以更有效率地獲取所需的技術和專業知識。
Q5:生成式 AI 和大型語言模型 (LLM) 在資安方面有何特殊風險?
A5:生成式 AI 和 LLM 主要帶來以下特殊風險:
- 惡意提示注入 (Prompt Injection): 攻擊者透過精心設計的提示來劫持模型的行為,使其洩露敏感資訊、生成惡意內容或繞過安全準則。
- 數據洩露: LLM 可能在訓練過程中無意中記住了部分訓練數據,導致在推斷時洩露隱私數據。
- 內容生成風險: 模型可能被誘導生成虛假資訊、釣魚郵件、惡意代碼、歧視性言論等,造成社會影響或資安風險。
- 模型誤用: 員工或使用者不慎將機密資訊輸入公開 LLM,導致資訊外洩。 防禦這些風險需要結合提示工程、模型行為監控、內容過濾和嚴格的使用策略。
9. 結論:擁抱 AI 創新,同時築牢數位防線
人工智慧的發展勢不可擋,它為企業帶來了前所未有的轉型機遇。然而,伴隨 AI 廣泛應用而來的資安風險,也成為企業必須正視的新常態。從數據投毒到對抗性攻擊,從不安全的 API 到惡意提示注入,AI 資安風險的層次豐富且複雜,任何一個環節的疏忽都可能導致嚴重的後果。
正如美國國家標準與技術研究院 (NIST) AI 風險管理框架所強調的:「AI 的潛在利益伴隨著潛在風險。風險管理方法應全面且持續地應用於 AI 生命週期的各個階段。」這意味著企業不能僅將 AI 資安視為一個單點問題,而應將其融入企業的整體資安治理框架,建立一套從數據、模型、應用到基礎設施和人員管理的全面、多層次防禦體系。
💡 想要偵測企業或公司網站有什麼資安漏洞嗎?

立即與我們聯繫,由專業團隊為您量身打造屬於您的安全堡壘。
📝 【立即填寫諮詢表單】我們收到後將與您聯繫。
LINE:@694bfnvw
📧 Email:effectstudio.service@gmail.com
📞 電話:02-2627-0277
🔐專屬您的客製化資安防護 —
我們提供不只是防禦,更是數位韌性打造
資安不是等出事才處理,而是該依據每間企業的特性提早佈局。
 在數位時代,資安不再只是「大企業」的專利,而是每個品牌都必須重視的底層競爭力。
在數位時代,資安不再只是「大企業」的專利,而是每個品牌都必須重視的底層競爭力。
我們深知,每一家企業的規模、產業環境與運作流程都截然不同,我們能協助您重新盤點體質,從風險控管、技術部署到團隊培訓,全方位強化企業抗壓能力,打造只屬於您公司的資安防護方案,從今天開始降低未爆彈風險。不只防止攻擊,更能在變局中穩健前行,邁向數位未來。
為什麼選擇我們?
✅ 量身打造,精準對應您的風險與需求
我們不提供千篇一律的方案,而是深入了解您的業務與系統架構,設計專屬的防護藍圖。
✅ 細緻專業,從技術到人員全方位防護
結合最新科技與實務經驗,不僅守住系統,更提升整體資安韌性。
✅ 透明溝通,專人服務無縫對接
每一步都有專屬顧問協助,確保您能理解每項風險與解決方案。
本文由影響視覺科技資安專家團隊撰寫,如需轉載請註明出處。更多資安知識分享,請關注我們的官方網站。
Leave a Reply